
民放のみならず、最近ではNHKの一部も対応するようになった公式見逃し配信ポータルサイトTVer。ほとんどの番組はGYAOでも配信されているが、放送局独自の見逃しサービス以外ではここでしか見られないものも一部ある。
しかしGYAOとは違ってTVerはyoutube-dlに対応していないので、そのままではmpv等のメディアプレーヤーで視聴したり、ローカルに保存して後から見たりできない。動画自体はHLSで配信されているようなので、ブラウザのリクエストを覗いてm3u8ファイルのURLを検索しmpvでURLを開けば視聴できるが、面倒だ。
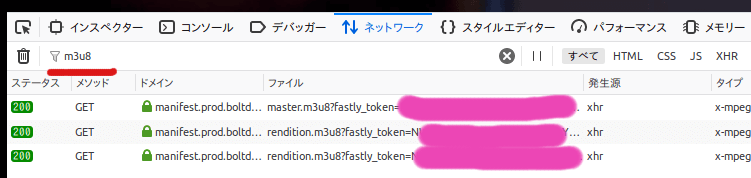
このm3u8ファイルだが、TVerではmanifest.prod.boltdns.netというドメインから配信されている。なんだか見覚えがあると思ったらGYAOと同じだ。実はGYAOもm3u8ファイルがmanifest.prod.boltdns.netから配信されている。GYAOはbrightcoveというプラットフォームを利用しているので、つまりTVerもbrighcoveを利用しているということだ。
youtube-dlはbrightcaveに対応しているので、うまくやればTVerもイケると思いyoutube-dlのpythonで書かれたbrightcave用エキストラクターやTVerのplayer jsなどを見ながらアレコレ試していたらyoutube-dlからTVerが利用できるようになった。
例えば下のサンプルをtver.pyとして保存してmpv "$(./tver.py https://tver.jp/episode/1234567)"やyoutube-dl -o "あとで見る.%(ext)s" "$(./tver.py https://tver.jp/episode/1234567)"のようにして使うと便利。
#!/usr/bin/env python3
"""
CC0で公開する https://creativecommons.org/publicdomain/zero/1.0/deed.ja
"""
import re
from urllib.request import urlopen
import argparse
def extract(htm):
"""tverのhtmlからidなどを抽出する"""
pattern = r"""^\s+addPlayer\(\n"""\
r"""\s+'(?P<player_id>[\da-zA-Z]*)',\n"""\
r"""\s+'(?P<player_key>[\da-zA-Z]*)',\n"""\
r"""\s+'(?P<catchup_id>[\da-zA-Z]*)',\n"""\
r"""\s+'(?P<publisher_id>[a-z\d]*)',\n"""\
r"""\s+'(?P<reference_id>[\da-zA-Z_-]*)',\n"""\
r"""\s+'(?P<title>[^']+)',\n"""\
r"""\s+'(?P<sub_title>[^']*)',\n"""\
r"""\s+'(?P<service>[a-z]+)',\n"""\
r"""\s+'(?P<service_name>[^']+)',\n"""\
r"""\s+(?P<sceneshare_enabled>true|false),\n"""\
r"""\s+(?P<share_start>\d+)"""
m = re.search(pattern, htm, re.M)
if not m:
raise Exception("ids not found")
else:
data = m.groupdict()
url = ""
if data["service"] == "cx" and data.get("publisher_id", ""):
#フジテレビオンデマンド
url = f'https://i.fod.fujitv.co.jp/abr/pc_html5/{data["publisher_id"]}.m3u8'
#reference_id, publisher_id, player_keyが必要
elif data.keys() >= {"reference_id", "publisher_id", "player_key"}:
url = f'http://players.brightcove.net/{data["publisher_id"]}/{data["player_key"]}_default/index.html?videoId=ref:{data["reference_id"]}'
else:
raise Exception("one of ids not found")
return url
def dl(url):
"""getでリスエストを出してレスポンスを返す"""
with urlopen(url) as req:
return req.read().decode('utf-8')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("urls", nargs="+", help="tver url")
args = parser.parse_args()
for url in args.urls:
html = dl(url)
print(extract(html))ちなみに正規表現のtitleやsub_titleというグループで番組名や各エピソードタイトルをキャプチャしているのでyoutube-dlに渡して保存する場合に利用してもいいかもしれません。楽しい📺ライフを!